from matplotlib import pyplot as plt
import torch
import deep_tensor as dt
from examples.heat import setup_heat_problem, plot_dl_functionHeat Equation
Here, we characterise the posterior distribution of the diffusion coefficient of a two-dimensional heat equation. We will consider a similar setup to that described in Cui and Dolgov (2022).
Problem Setup
We consider the domain \(\Omega := (0, 3) \times (0, 1)\), with boundary denoted by \(\partial \Omega\). The change in temperature, \(u(\boldsymbol{x}, t)\), at each point in the domain over time can be modelled by the heat equation,
\[ \frac{\partial u(\boldsymbol{x}, t)}{\partial t} = \nabla \cdot (\kappa(\boldsymbol{x}) \nabla u(\boldsymbol{x}, t)) + f(\boldsymbol{x}, t), \quad \boldsymbol{x} \in \Omega, t \in (0, T], \]
where \(\kappa(\boldsymbol{x})\) denotes the (spatially varying) diffusion coefficient, and \(f(\boldsymbol{x}, t)\) denotes the forcing term, which models heat sources or sinks. We set the end time to \(T = 10\), and impose the initial and boundary conditions
\[ \begin{align} u(\boldsymbol{x}, 0) &= 0, \qquad \boldsymbol{x} \in \Omega, \\ \frac{\partial \kappa(\boldsymbol{x}) u(\boldsymbol{x}, t)}{\partial \boldsymbol{n}} &= 0, \qquad \boldsymbol{x} \in \partial\Omega. \end{align} \]
In the above, \(\boldsymbol{n}\) denotes the outward-facing normal vector on the boundary of the domain.
We assume that the forcing term is given by
\[ f(\boldsymbol{x}, t) = c \left(\exp\left(−\frac{1}{2r^{2}}||\boldsymbol{x} − \boldsymbol{a}||^{2}\right) − \exp\left(-\frac{1}{2r^{2}}||\boldsymbol{x} − \boldsymbol{b}||^{2}\right)\right), \]
where \(\boldsymbol{a} = \begin{bmatrix} 1/2, 1/2 \end{bmatrix}^{\top}\), \(\boldsymbol{b} = [5/2, 1/2]^{\top}\), and \(c = 5 \pi \times 10^{-2}\).
Prior Density
We endow the logarithm of the unknown diffusion coefficient with a process convolution prior; that is,
\[ \log(\kappa(\boldsymbol{x})) = \log(\bar{\kappa}(\boldsymbol{x})) + \sum_{i=1}^{d} \xi^{(i)} \exp\left(-\frac{1}{2r^{2}}\left\lVert\boldsymbol{x} - \boldsymbol{x}^{(i)}\right\rVert^{2}\right), \]
where \(d=27\), \(\log(\bar{\kappa}(\boldsymbol{x}))=-5\), \(r=1/16\), the coefficients \(\{\xi^{(i)}\}_{i=1}^{d}\) are independent and follow the unit Gaussian distribution, and the centres of the kernel functions, \(\{\boldsymbol{x}^{(i)}\}_{i=1}^{d}\), form a grid over the domain (see Figure 1).
Data
To estimate the diffusivity coefficient, we assume that we have access to measurements of the temperature at 13 locations in the model domain (see Figure 2), recorded at one-second intervals. This gives a total of 130 measurements. All measurements are corrupted by i.i.d. Gaussian noise with zero mean and a standard deviation of \(\sigma=1.65 \times 10^{-2}\).
Implementation in \(\texttt{deep\_tensor}\)
We will now use \(\texttt{deep\_tensor}\) to construct a DIRT approximation to the posterior. To accelerate this process, we will use a reduced order model in place of the full model. Then, we will illustrate some debiasing techniques which use the DIRT approximation to the posterior, in combination with the full model, to accelerate the process of drawing exact posterior samples.
We begin by defining the prior, (full) model and reduced order model.
The full model is implemented in FEniCS, on a \(96 \times 32\) grid, using piecwise linear basis functions. Timestepping is done using the backward Euler method. The reduced order model is constructed using the proper orthogonal decomposition (see, e.g., Benner, Gugercin, and Willcox 2015).
# Construct the prior, full model and reduced order model
prior, model_full, model_rom = setup_heat_problem()Next, we will generate the true log-diffusion coefficient using a sample from the prior. The true log-diffusion coefficient is plotted in Figure 1.
xi_true = torch.randn(prior.dim)
logk_true = prior.transform(xi_true)Code
fig, ax = plt.subplots(figsize=(6.0, 2.0))
cbar_label = r"$\log(\kappa(\bm{x}))$"
plot_dl_function(fig, ax, model_full.vec2func(logk_true), cbar_label)
ax.scatter(*prior.ss.T, s=16, c="k", marker="x")
ax.set_xlabel(r"$x_{0}$")
ax.set_ylabel(r"$x_{1}$")
plt.show()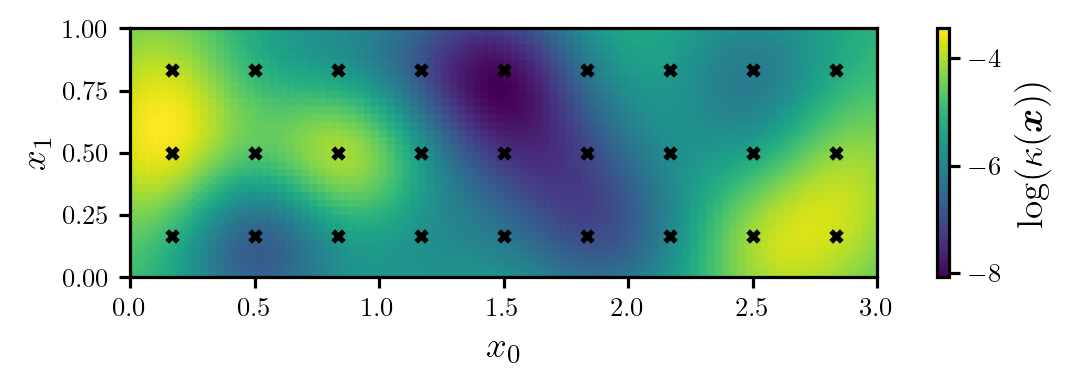
Next, we will solve the (full) model to obtain the modelled temperatures corresponding to the true diffusion coefficient, and use these to generate some synthetic data. Figure 2 shows the true temperature field at time \(T=10\), as well as the observation locations.
# Generate true temperature field
u_true = model_full.solve(logk_true)
# Specify magnitude of observation noise
std_error = 1.65e-2
var_error = std_error ** 2
# Extract true temperatures at the observation locations and add
# observation noise
d_obs = model_full.observe(u_true)
noise = std_error * torch.randn_like(d_obs)
d_obs += noiseCode
fig, ax = plt.subplots(figsize=(6.0, 2.0))
cbar_label = r"$u(\bm{x}, 10)$"
plot_dl_function(fig, ax, model_full.vec2func(u_true[:, -1]), cbar_label, vmin=-0.15, vmax=0.10)
ax.scatter(*model_full.xs_obs.T, s=16, c="k", marker=".")
ax.set_xlabel(r"$x_{0}$")
ax.set_ylabel(r"$x_{1}$")
plt.show()
Building the DIRT Object
Now we will build a DIRT object to approximate the posterior density of the coefficients, \(\{\xi^{(i)}\}_{i=1}^{d}\), used to parametrise the log-diffusion coefficient, for the reduced-order model. We begin by defining functions which return the potential associated with the likelihood and prior.
def neglogpri(xs: torch.Tensor) -> torch.Tensor:
"""Returns the negative log prior density evaluated a given set of
samples.
"""
return 0.5 * xs.square().sum(dim=1)
def _negloglik(model, xs: torch.Tensor) -> torch.Tensor:
"""Returns the negative log-likelihood, for a given model,
evaluated at each of a set of samples.
"""
neglogliks = torch.zeros(xs.shape[0])
for i, x in enumerate(xs):
k = prior.transform(x)
us = model.solve(k)
d = model.observe(us)
neglogliks[i] = 0.5 * (d - d_obs).square().sum() / var_error
return neglogliks
def negloglik_full(xs: torch.Tensor) -> torch.Tensor:
"""Returns the negative log-likelihood for the full model (to be
used later).
"""
return _negloglik(model_full, xs)
def negloglik_rom(xs: torch.Tensor) -> torch.Tensor:
"""Returns the negative log-likelihood for the reduced-order model."""
return _negloglik(model_rom, xs)Next, we specify a preconditioner. Because the prior of the coefficients \(\{\xi^{(i)}\}_{i=1}^{d}\) is the standard Gaussian, the mapping between a Gaussian reference and the prior is simply the identity mapping. This is an appropriate choice of preconditioner in the absence of any other information.
reference = dt.GaussianReference()
preconditioner = dt.IdentityMapping(prior.dim, reference)Next, we specify a polynomial basis.
poly = dt.Legendre(order=20)Finally, we can construct the DIRT object.
# Reduce the initial and maximum tensor ranks to reduce the cost of each layer
tt_options = dt.TTOptions(init_rank=12, max_rank=12)
dirt = dt.DIRT(
negloglik_rom,
neglogpri,
preconditioner,
poly,
tt_options=tt_options
)[DIRT] Iter: 1 | Cum. Fevals: 2.00e+03 | Cum. Time: 3.06e+00 s | Beta: 0.0001 | ESS: 0.9961
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 27468 | 5 | 1.00000e+00 | 1.00000e+00 | 1.03963e-03 | 9.41136e-04
[ALS] ALS complete.
[DIRT] Iter: 2 | Cum. Fevals: 5.89e+04 | Cum. Time: 4.92e+01 s | Beta: 0.0098 | ESS: 0.5142 | DHell: 0.0027
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 9177 | 5 | 1.90757e+00 | 1.70725e-01 | 1.25553e-01 | 1.65646e-01
[ALS] ALS complete.
[DIRT] Iter: 3 | Cum. Fevals: 7.93e+04 | Cum. Time: 6.84e+01 s | Beta: 0.0366 | ESS: 0.4854 | DHell: 0.1003
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 16926 | 7 | 4.98581e-01 | 1.00157e-01 | 6.47549e-02 | 7.16710e-02
[ALS] ALS complete.
[DIRT] Iter: 4 | Cum. Fevals: 1.15e+05 | Cum. Time: 1.03e+02 s | Beta: 0.0972 | ESS: 0.4865 | DHell: 0.1132
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 26565 | 9 | 7.91892e-01 | 8.61927e-02 | 8.42892e-02 | 7.61682e-02
[ALS] ALS complete.
[DIRT] Iter: 5 | Cum. Fevals: 1.70e+05 | Cum. Time: 1.57e+02 s | Beta: 0.2122 | ESS: 0.4645 | DHell: 0.1121
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 40005 | 11 | 1.57709e+00 | 1.47383e-01 | 8.62617e-02 | 7.01763e-02
[ALS] ALS complete.
[DIRT] Iter: 6 | Cum. Fevals: 2.52e+05 | Cum. Time: 2.41e+02 s | Beta: 0.4001 | ESS: 0.5029 | DHell: 0.1148
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 51723 | 13 | 2.19170e+00 | 1.13862e-01 | 7.68353e-02 | 7.12904e-02
[ALS] ALS complete.
[DIRT] Iter: 7 | Cum. Fevals: 3.58e+05 | Cum. Time: 3.53e+02 s | Beta: 0.7545 | ESS: 0.4548 | DHell: 0.1383
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 58275 | 14 | 1.48638e+01 | 6.13150e-01 | 6.67197e-02 | 7.34199e-02
[ALS] ALS complete.
[DIRT] Iter: 8 | Cum. Fevals: 4.76e+05 | Cum. Time: 4.79e+02 s | Beta: 1.0000 | ESS: 0.3561 | DHell: 0.1953
[ALS] Iter | Func Evals | Max Rank | Max Local Error | Mean Local Error | Max Debug Error | Mean Debug Error
[ALS] 1 | 65121 | 14 | 8.79746e-01 | 9.50211e-02 | 2.65095e-02 | 3.83064e-02
[ALS] ALS complete.
[DIRT] DIRT construction complete.
[DIRT] • Layers: 8.
[DIRT] • Total function evaluations: 608,520.
[DIRT] • Total time: 10.84 mins.
[DIRT] • DHell: 0.2084.Debiasing
We will now use the DIRT density as the proposal density for an independence MCMC sampler. This will allow us to sample exactly from the posterior associated with the full model.
# Generate a set of samples from the DIRT density
rs = dirt.reference.random(d=dirt.dim, n=5000)
xs, potentials_dirt = dirt.eval_irt(rs)
# Evaluate the true potential function (for the full model) at each sample
potentials_exact = neglogpri(xs) + negloglik_full(xs)
# Run independence sampler
res = dt.run_independence_sampler(xs, potentials_dirt, potentials_exact)
print(f"Acceptance rate: {res.acceptance_rate:.2f}")
print(f"Mean IACT (all parameters): {res.iacts.mean():.2f}")
print(f"Maximum IACT (all parameters): {res.iacts.max():.2f}")Acceptance rate: 0.72
Mean IACT (all parameters): 2.53
Maximum IACT (all parameters): 3.57For all parameters, the integrated autocorrelation time (IACT) is small, which suggests that the sampler is moving around the posterior efficiently. Figure 3 shows trace plots for the log-posterior density and selected parameters, which reinforces this idea.
Code
parameters = torch.hstack((res.potentials[:, None], res.xs[:, 21:23]))
ylabels = [r"$-\log(f(x))$", r"$\xi_{22}$", r"$\xi_{23}$"]
fig, axes = plt.subplots(1, 3, figsize=(7.5, 3))
for i, ax in enumerate(axes):
ax.plot(parameters[:, i], c="tab:red", lw=0.5)
ax.set_ylabel(ylabels[i])
ax.set_box_aspect(1)
add_arrows(ax)
axes[1].set_xlabel("Iteration")
plt.show()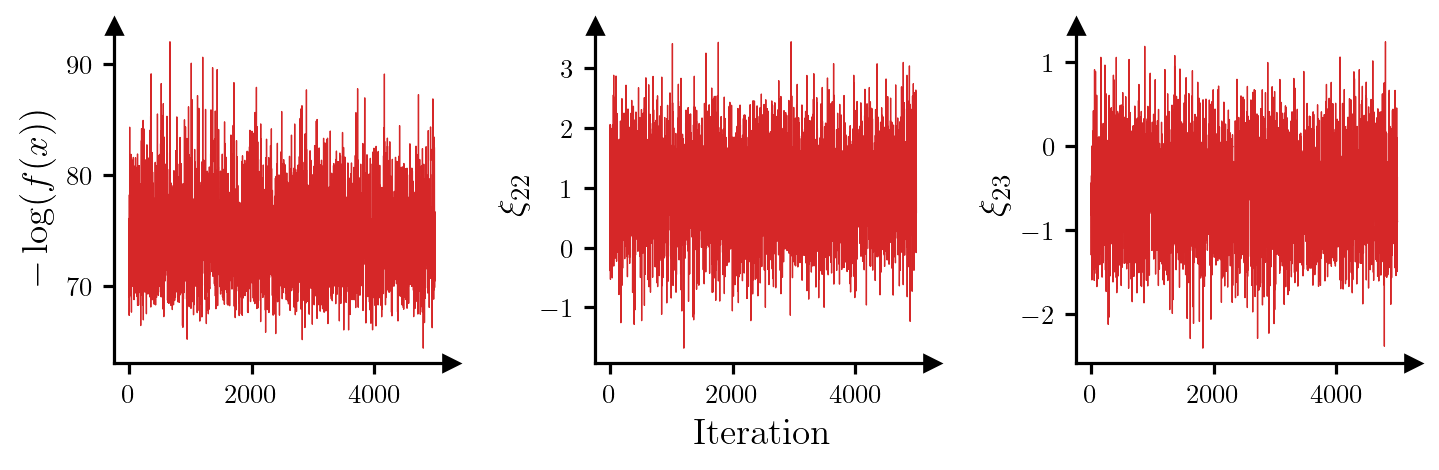
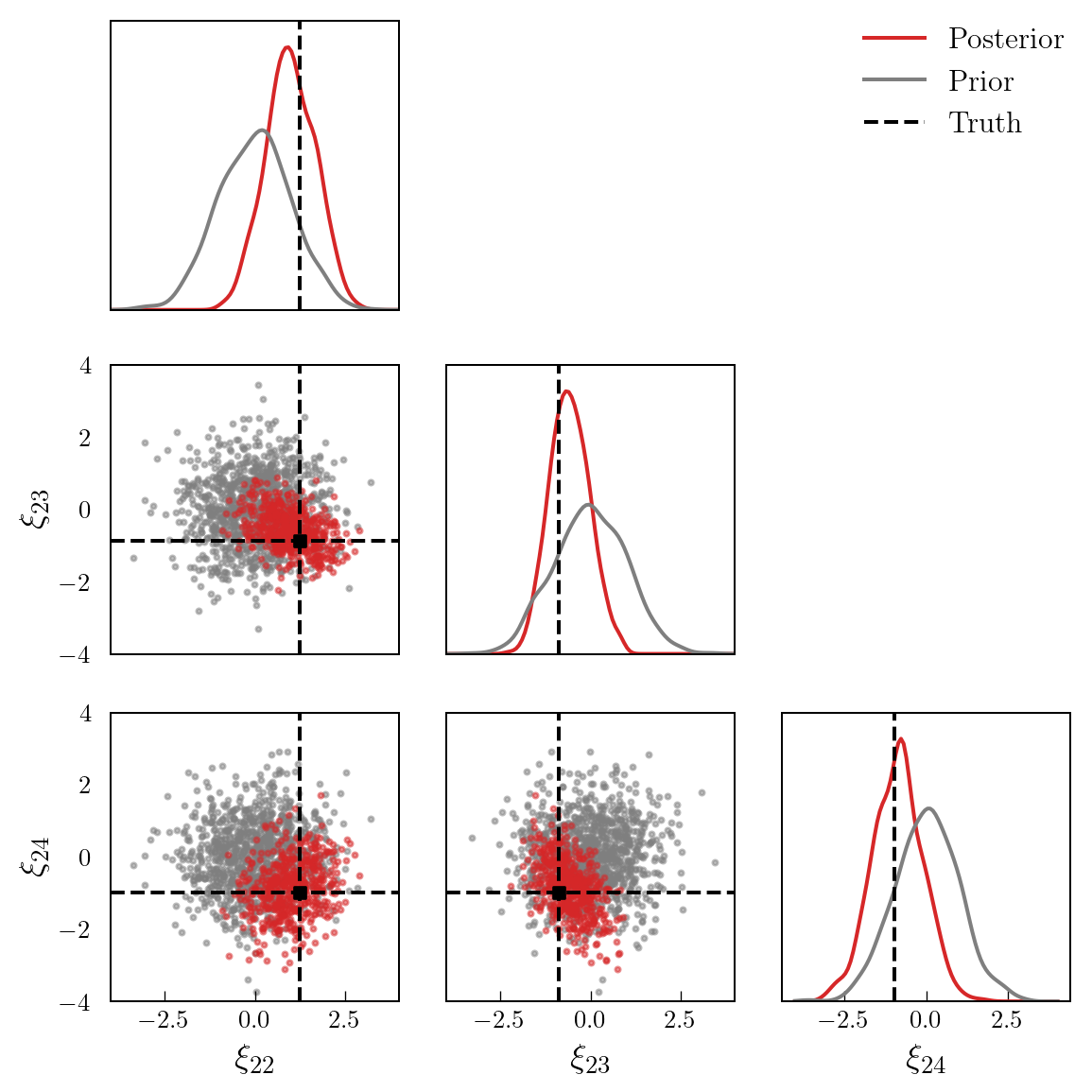
Finally, Figure 4 shows a set of prior and posterior samples for three selected coefficients. It is evident that the posterior is significantly different to the prior.
Code
xs_pri = dirt.reference.random(d=dirt.dim, n=1000)
xs_post = res.xs[::10]
labels = [r"$\xi_{"+f"{i}"+r"}$" for i in range(22, 25)]
bounds = torch.tensor([[-4.0, 4.0], [-4.0, 4.0], [-4.0, 4.0]])
pairplot(
xs_post[:, 21:24],
xs_pri[:, 21:24],
truth=xi_true[21:24],
labels=labels,
x_label="Posterior",
y_label="Prior",
bounds=bounds
)
References
Benner, Peter, Serkan Gugercin, and Karen Willcox. 2015. “A Survey of Projection-Based Model Reduction Methods for Parametric Dynamical Systems.” SIAM Review 57 (4): 483–531. https://doi.org/10.1137/13093271.
Cui, Tiangang, and Sergey Dolgov. 2022. “Deep Composition of Tensor-Trains Using Squared Inverse Rosenblatt Transports.” Foundations of Computational Mathematics 22 (6): 1863–1922. https://doi.org/10.1007/s10208-021-09537-5.